SNS API
先日公開された新しい Twitter APIのv2 では、特定のツイートにいいねしたユーザーの情報や、あるユーザーがいいねした投稿データを抽出することができるようになりました。
今回はこちらのAPIでデータを取得する下記2つの方法を解説していきます。
| 機能 | エンドポイント | |
| Users who have liked a Tweet | 特定のツイートにいいねしたユーザーを抽出 | /2/tweets/:id/liking_users |
| Tweets liked by a user | 特定のユーザーがいいねした | /2/users/:id/liked_tweets |
なおv2は無料な一方で取得できるデータが限られていたりするため、投稿データを完全取得する際は下記などのプレミアムAPIをご参照ください。
特定の投稿にいいねしたユーザーを抽出する
今回のデータ取得の対象は下記投稿を例に取り上げてみます。
この安倍元首相の投稿には現在15万件以上のいいねがついています。このいいね情報を取得するには、Twitter上では下記のいいねの場所をクリックすると取得することができます。今日のデザートはパイナップル。とっても美味しそう。
— 安倍晋三 (@AbeShinzo) 午前2:11 · 2021年4月28日
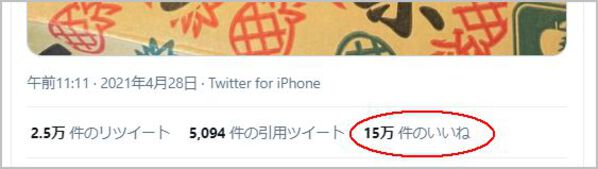
今回はこの情報をAPIで取ってきます。
APIを叩く
import requests
import json
# bearer_tokenを設定(デベロッパーポータルのd ash boardから入手できる)
bearer_token = "xxxxxxxxx"
# headerにbearer tokenを設定
headers = {"Authorization": "Bearer {}".format(bearer_token)}
# 取得したい項目をオプションで設定
# "user.fields"でいいねしたユーザーの情報を取得する
params = {
"user.fields": "created_at,description,entities,id,location,name,pinned_tweet_id,profile_image_url,protected,public_metrics,url,username,verified,withheld"
}
# ツイートIDを設定
id = "1387227856611069952"
# urlを設定(いいねしたユーザー情報は末尾urlがliking_usersとなる)
url = "https://api.twitter.com/2/tweets/{}/liking_users".format(id)
# 設定情報をリクエスト
res = requests.get(url, headers=headers, params = params)
# jsonとして読み込む
res_text = res.text
likes = json.loads(res_text)
取得できるデータ
実際に取得できるデータは下記となります。
{
"name": "広報PR代行サービス【PRナビ】| 株式会社ガーオン",
"verified": False,
"entities": {
"url": {
"urls": [\
{\
"start": 0,\
"end": 23,\
"url": "https://t.co/QWIMMW7lid",\
"expanded_url": "/",\
"display_url": "/"\
}\
]
},
"description": {
"urls": [\
{\
"start": 104,\
"end": 127,\
"url": "https://t.co/zRJSJCTPM2",\
"expanded_url": "/blog",\
"display_url": "/blog"\
},\
{\
"start": 138,\
"end": 161,\
"url": "https://t.co/4LfK0XP6a1",\
"expanded_url": "http://prnavi.jp",\
"display_url": "prnavi.jp"\
}\
]
}
},
"url": "https://t.co/QWIMMW7lid",
"username": "PR_NAVi",
"description": "【まるごと広報代行サービス PRナビ】一部上場企業からスタートアップまで累計400社以上の広報PRを支援 | 企業や団体が発信する日々のプレスリリースを発信中 | SNS等のデータ収集・分析 | PRブログ:https://t.co/zRJSJCTPM2 | リリースサイト:https://t.co/4LfK0XP6a1",
"profile_image_url": "https://pbs.twimg.com/profile_images/628090809686949888/jeE0Tn_u_normal.png",
"protected": False,
"id": "102654697",
"created_at": "2010-01-07T11:47:13.000Z",
"public_metrics": {
"followers_count": 7088,
"following_count": 7239,
"tweet_count": 3718,
"listed_count": 45
},
"location": "東京都品川区"
},
locationなどにユーザーが設定した地理情報が含まれているため、ここからいいねしたユーザーの地理分布などを分析できそうです。
しかしこのAPIは取得できるデータがMAX100件(なぜか調子が悪いと100件未満となる)となっているため、今回はいいねしたユーザーのdescription(自己紹介)をワードクラウドにしてみたいと思います。
自己紹介文をワードクラウド化

上記情報に加え地理情報などを見てみても、台湾からいいねされている傾向が強いことが分かります。
MAX100件ということで、何に使えば良いのか分かりませんが、以上が特定の投稿にいいねしたユーザーの情報を取得する方法でした。
次回は、特定のユーザーがいいねした投稿を抽出する方法を解説します。
当社では広報活動のサポートの他、Twitterのデータ取得や分析、各種ダッシュボード作成などもサポートしています。 お問い合せフォーム よりお気軽にお問い合せください。
▼合わせて読みたい