この記事の要点
- 2026年4月、バイブコーディングの名付け親カーパシーが「LLM wiki」をGistで公開。RAGの弱点(チャンク分断・蓄積されない検索)を、知識の書き方そのもので解決する新しい運用法として話題に
- 3層構造(Raw sources + The wiki + The schema)と3つの操作(Ingest/Query/Lint)で運用。実装はObsidian+Claude Codeの組み合わせが定番
- 広報PR業務はエンティティと関係性の塊。記者・媒体・キャンペーンの蓄積を複利的に育てる仕組みとして相性が良い
LLM wikiとは何か
2026年4月、AI研究者でバイブコーディング(vibe coding)の名付け親でもあるアンドレイ・カーパシー(Andrej Karpathy)が、新しい個人ナレッジベースの運用法「LLM wiki」を自身のGistで公開しました。AI界隈で大きな話題になっています。
LLM wikiは、原典をそのまま保存し、要点抽出と相互リンクをLLMに任せることで知識のネットワークを育てていく方式です。書くのは原則としてLLM。人間は「この情報を取り込んで」「あの件について教えて」と頼むだけで済みます。
カーパシーがこの方式を「RAGの弱点(チャンクで文脈が壊れる、毎回ゼロから検索される)を、知識の書き方そのもので解消する別レイヤーの運用法」として提唱したことで、AIナレッジ構築の新しい選択肢として注目を集めました。特に蓄積データと文脈が成果を左右する広報・PR業務には、この方式が極めて相性が良いのです。
本記事では、LLM wikiの3層構造を非エンジニアにも分かるよう詳説し、PR業務に最適な理由と、現実的な弱点まで踏み込んで解説します。
カーパシーって誰?
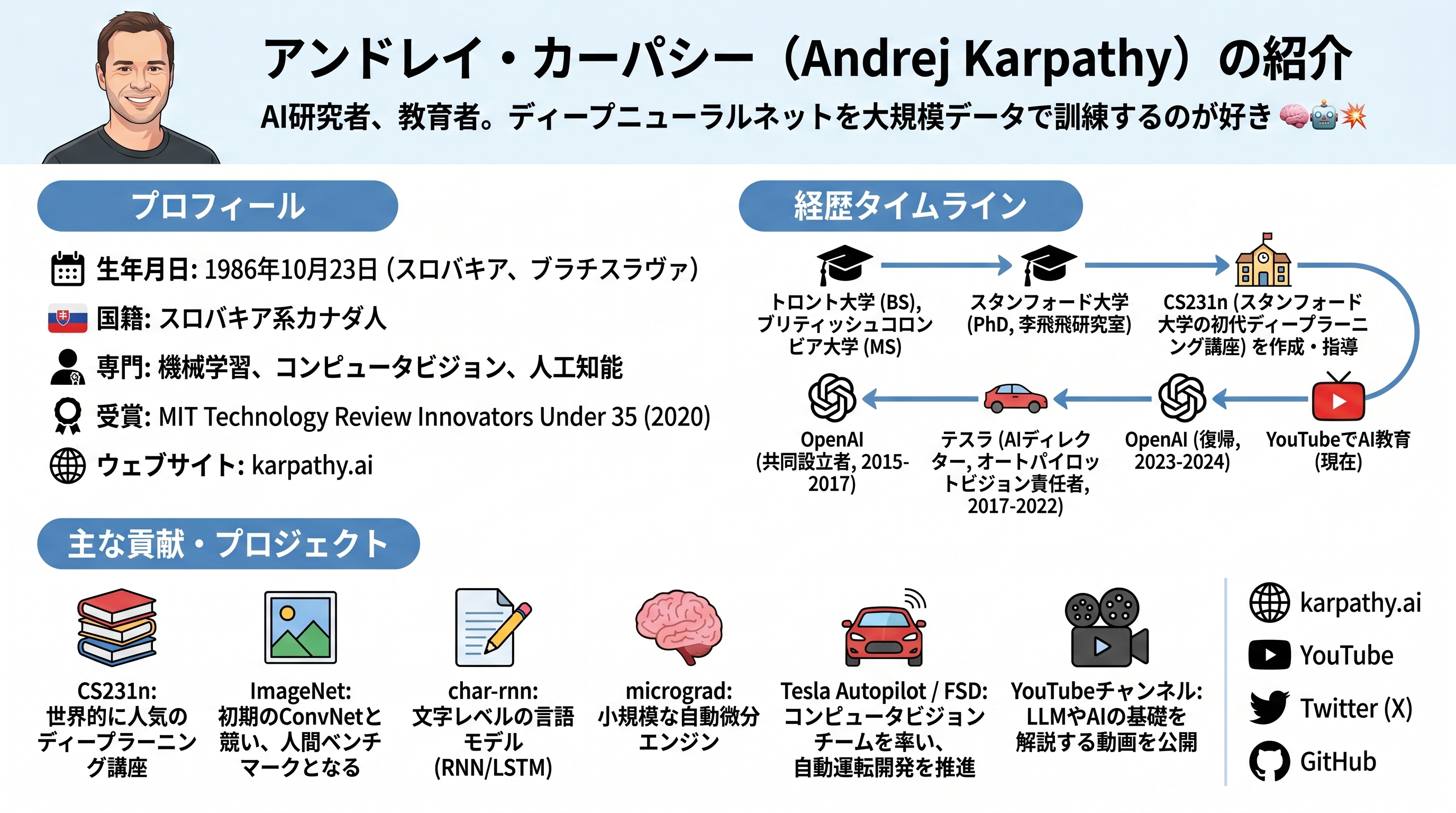
カーパシーはAI業界で最も影響力のある研究者の一人です。OpenAIの創業メンバーを経て、Teslaの自動運転AI部門のトップに就任。現在は教育系AIスタートアップ「Eureka Labs」を創業しています。
彼の強みは、AI技術の本質を一般の言葉に翻訳する力です。だから発信はAI研究者だけでなく、一般のクリエイターや経営者にも広く読まれます。
2025年初頭に提唱した「バイブコーディング」も同じ路線でした。「自然言語で『こういうアプリが欲しい』と頼むだけでAIがコードを書く新しい開発スタイル」という概念です。日本でも開発者・非開発者問わず広く使われる言葉になりました。
そのカーパシーが2026年4月に出した次の一手が、LLM wikiでした。
RAGとLLM wikiの違い
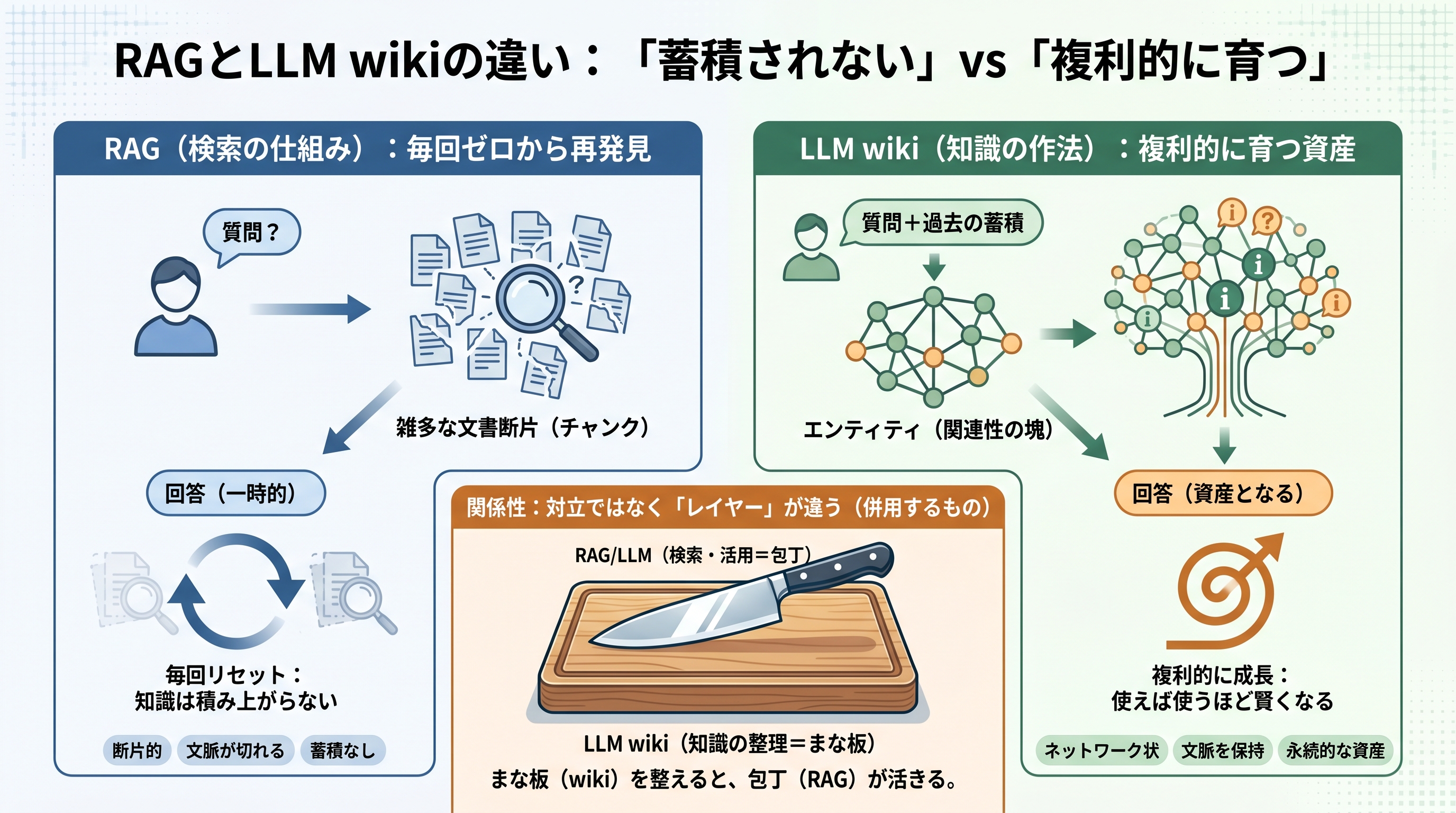
カーパシー曰く:RAGは「蓄積されない」
カーパシーがGistで最も強く批判しているのは、RAGの「精度」ではありません。知識が蓄積されないことです。
「LLMは質問のたびに、知識をゼロから再発見している」(the LLM is rediscovering knowledge from scratch on every question)。これがGistでの彼の表現です。
新しい質問が来たら、また同じ書類の山から関連断片を探し直す。前回の検索結果も、前回の回答も、何も残りません。5つの文書を統合して答えるような繊細な質問をすれば、LLMはその度に関連断片を探して繋ぎ合わせなければなりません。何も積み上がらない。NotebookLM、ChatGPTのファイルアップロード、ほとんどのRAGシステムはこの方式で動いています。
カーパシーの処方箋:「複利的に育つ成果物」
カーパシーが提唱するLLM wikiは、この「蓄積されない」問題への直接の処方箋です。Gistの中の言葉を借りるなら 永続的で、複利的に育つ成果物(persistent, compounding artifact)。
LLM wikiでは、取り込んだ素材も、ユーザーが投げた質問も、その回答も、ファイルとして残ります。1か月後、3か月後、半年後と、新しい素材を加えるたび、新しい質問をするたびに、wikiはますます豊かになっていきます。これが、PR業務のように「同じ記者と数年単位で関係を育てる」仕事と本質的に相性が良い理由です。
レイヤーが違うので、本来は併用するもの
RAGとLLM wikiは"対立する選択肢"ではありません。担当している層が違います。
- RAG は「取り出し方の仕組み」(retrieval layer)。雑多な文書から関連する断片を探してくる技術
- LLM wiki は「知識の書き方の作法」(content layer)。LLMが活かせる形で情報を整理しておくための型
つまり別のレイヤーに住んでいます。「包丁に代わる新しいまな板」ではなく、「まな板を整えると包丁が活きる」関係です。
両者の特徴を並べると、こう整理できます。
| 観点 | RAG(取り出しの仕組み) | LLM wiki(書き方の作法) |
|---|---|---|
| 担当する層 | 取り出し層 | コンテンツ層 |
| 保存形式 | チャンク(小さな断片) | エンティティ(1ファイル=1テーマ) |
| 書き手 | 人間が原典を投入、機械がチャンクに切る | 人間が原典を集め、LLMが整理 |
| 構造 | フラット(断片の集まり) | グラフ(リンクで繋がる) |
| 取り出し方 | 意味の近さで断片を抽出 | リンクをたどる+全文参照 |
| 人間が読むか | 読まない(LLM専用の中間データ) | 人間も読める(共通資産) |
| 文脈の保持 | チャンク境界で分断される | エンティティ単位で保たれる |
| 知識の蓄積 | 毎回ゼロから検索 | 持続的に蓄積・更新される |
| 厳格モードの組み込み | 仕組みとしてはない | schemaで明文化できる |
ここから見えてくるのが、RAGの弱点です。チャンクで文脈が壊れる、意味検索の網羅性に穴が出る、人間が読んで仕事に使えない、毎回ゼロから検索するため知識が蓄積しない。これらが特に痛いのが、関係性と継続的な文脈で勝負する広報業務です。
LLM wiki はこれらの弱点を、検索アルゴリズムを改良するのではなく、知識の書き方そのもので解消します。だから両者は競合せず、組み合わせると本領を発揮します。
LLM wikiの3層構造
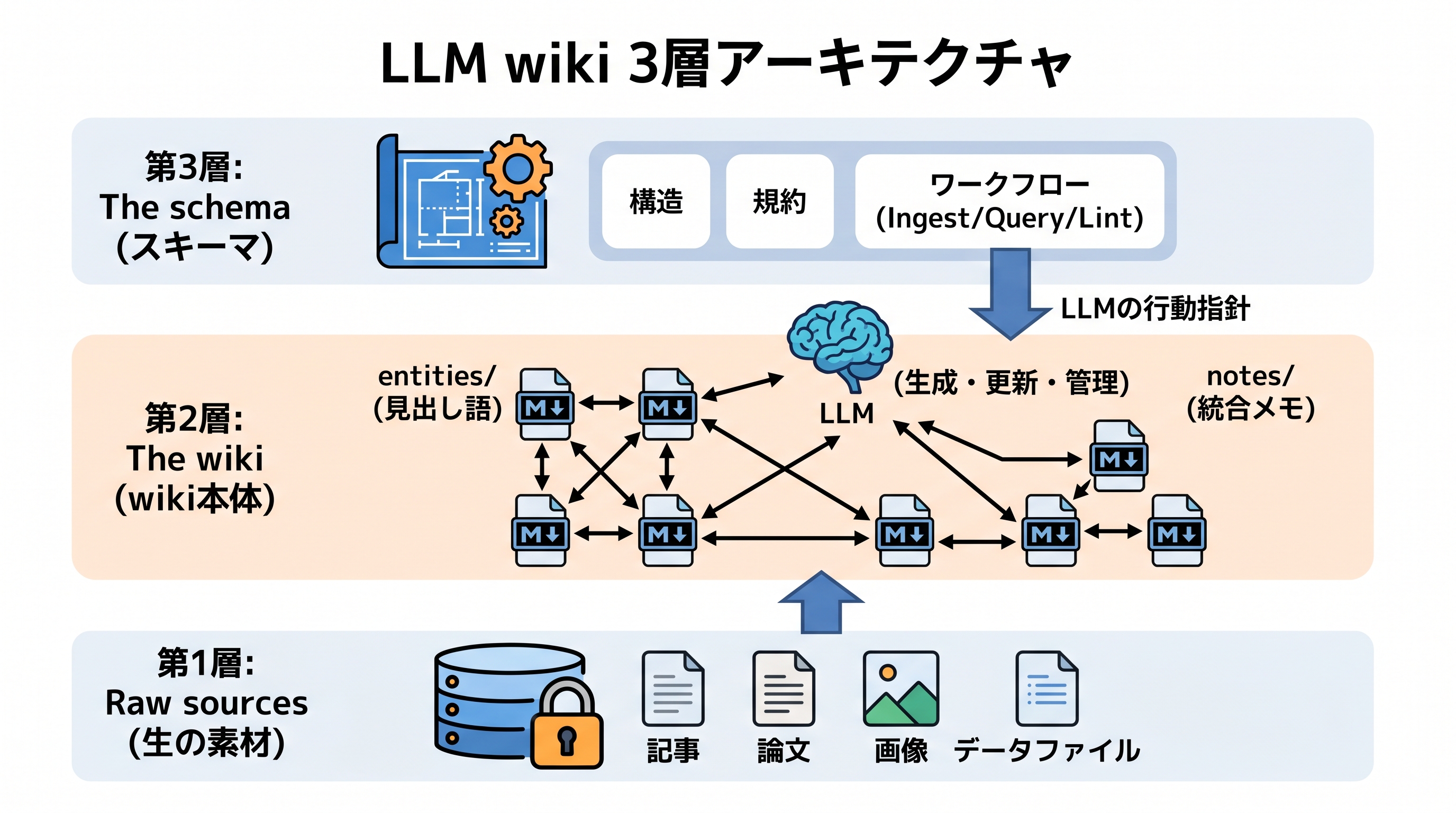
LLM wikiの中核は3層構造です。カーパシー本人がGistで「Raw sources」「The wiki」「The schema」の3つを明示しています。順に詳しく見ていきます。
第1層:Raw sources — 原典の置き場
raw/ は、元になった情報そのものを置く場所です。記事の本文コピー、PDFからの抜粋、会議の文字起こし、SNS投稿、メモ書きなど。加工せずそのまま保存するのが鉄則です。
なぜそのまま残すのか。理由は2つあります。
- 後から「元はどう書いてあったか」を確認できる
- 別の角度で読み直したい時に再解釈できる
第2層:The wiki — LLMが整理した本体
ここが知識のネットワーク本体です。raw/ の原典をLLMが読み、要点を抽出してこの第2層に書き出します。カーパシー原典では「LLMが生成したMarkdownファイル群」とだけ定義されていますが、実装によってはentities/ と notes/など、中身を性質ごとに2種類に分けると整理がしやすくなるようです。
entities/ — 「見出し語」のページ
人物・概念・ツール・会社・プロジェクトなど、それ自体が主役になるものを1ファイルにまとめます。
| ファイル名例 | 中身 |
|---|---|
Karpathy.md | カーパシー本人の経歴・主張・関連ページへのリンク |
LLM-wiki.md | LLM wikiという運用方式の定義・実装例 |
Obsidian.md | LLM wiki構築によく使われるツールの説明 |
notes/ — 統合メモ・調査結果
複数の raw/ を統合した要約や、特定テーマの調査メモを置きます。
| ファイル名例 | 中身 |
|---|---|
LLM-wikiの始め方.md | 始め方を初心者向けに整理 |
PR業務でのwiki活用調査.md | PR業界での応用例を収集 |
イメージ:PR業務向けwikiの中身
たとえば広報担当者がwikiを育てると、こんなファイル群になるでしょう。
entities/
├── 記者/
│ ├── 田中太郎(日経・IT領域).md
│ ├── 鈴木花子(東洋経済・スタートアップ).md
│ └── 佐藤次郎(ITmedia・AI領域).md
├── 媒体/
│ ├── 日経新聞.md
│ ├── 東洋経済オンライン.md
│ └── ITmedia NEWS.md
└── トピック/
├── 生成AI業界動向.md
└── スタートアップ調達トレンド.md
notes/
├── キャンペーン振り返り.md
├── 生成AI業界 主要プレイヤー整理.md
└── IT系記者 興味領域マッピング.md
各ファイルは [[wikilink]] で相互に繋がっています。たとえば「田中太郎.md」を開くと、本文中に [[日経新聞]] [[生成AI業界動向]] などのリンクが張られており、辿るだけで関連情報にアクセスできます。これがwiki構造の本質です。
第3層:The schema — 運用ルール本体
3層目は「運用ルールの正本」です。普通は CLAUDE.md などの名前で1ファイルだけ置きます。中身はこんな項目です。
- ファイル命名規則
- フロントマター(ファイル冒頭のメタ情報)の書式
- 取り込み時の絶対ルール
- カテゴリの定義
- 厳格モード(後述)の徹底事項
このschema層が「迷ったらここを見る」唯一の正本になります。3層目を変更すれば、wiki全体の運用が変わります。
LLM wikiを動かす『3つの操作』
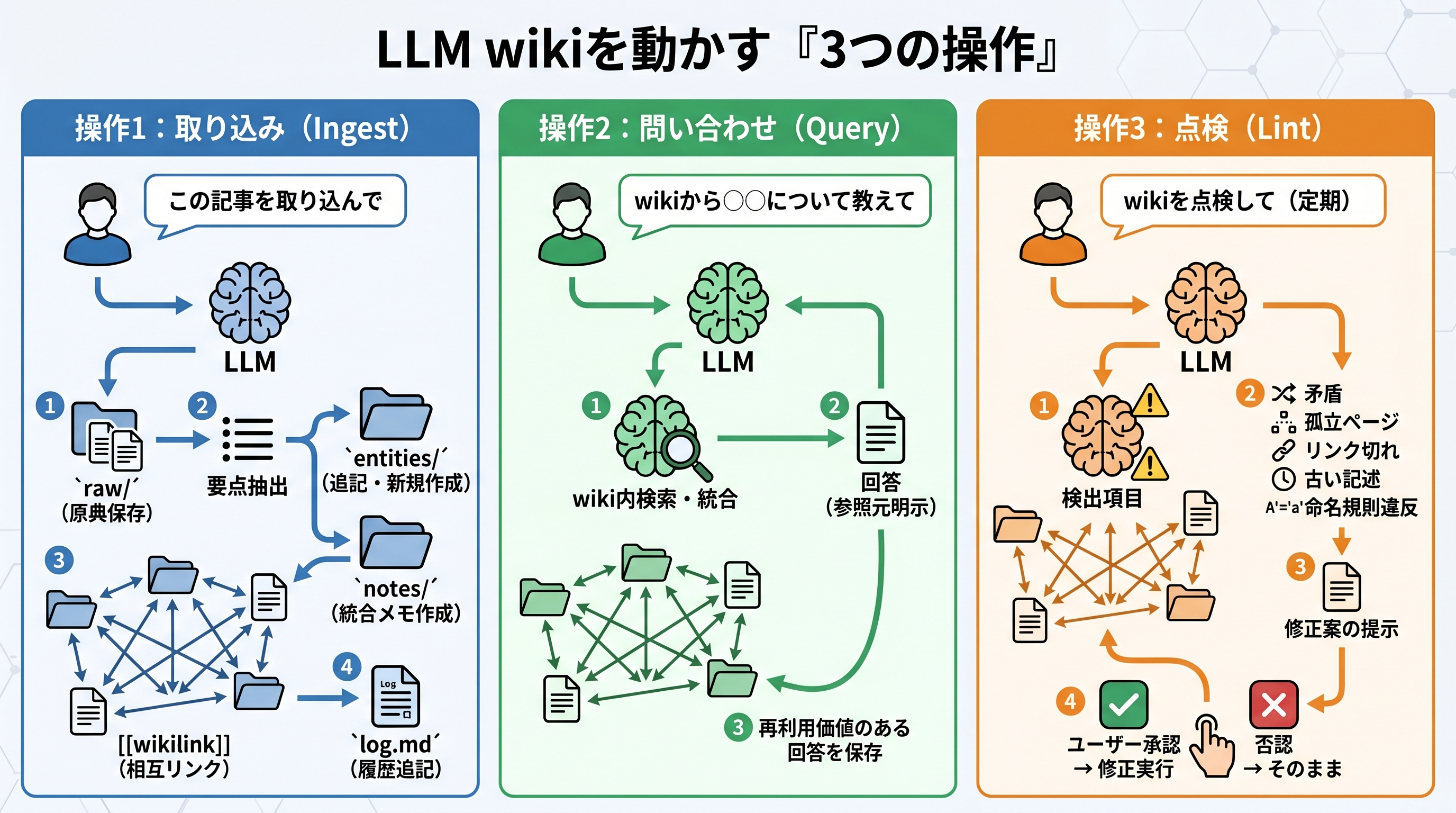
3層構造に対して、人間とLLMが行う操作は3種類です。これもカーパシーがGistで明示的に命名しています。
操作1:取り込み(Ingest)
ユーザーが「この記事を取り込んで」とLLMに頼むと、LLMが以下を実行します。
- 原典を
raw/に保存(フロントマター付き、本文は加工しない) - ファイル末尾に「要点」セクションを設け、3〜10個の箇条書きで重要点を抽出
- 関連する人物・概念・ツールを
entities/に追記または新規作成 - 必要なら
notes/に統合メモを作成 - すべて
[[wikilink]]で相互にリンクする - 取り込み履歴を
log.mdに1行追記
操作2:問い合わせ(Query)
「wikiから〇〇について教えて」とLLMに聞くと、こう動きます。
- wiki内を検索して関連ページを探す
- 見つかった情報を統合し、参照したページ名を明示しつつ回答
- 再利用価値のある回答は
notes/に保存して関連エンティティからリンク
操作3:点検(Lint)
「wikiを点検して」と頼むと、定期メンテナンスが走ります。検出する項目は以下です。
- 矛盾(同じ事項について異なるページで食い違う記述)
- 孤立ページ(どこからもリンクされていないページ)
- リンク切れ(参照先が存在しない
[[...]]) - 古い記述(6か月以上更新されていないノート)
- 命名規則違反
修正は自動でやらず、必ずユーザーの承認を得ます。
PR業務での具体例:3操作が回るとどうなるか
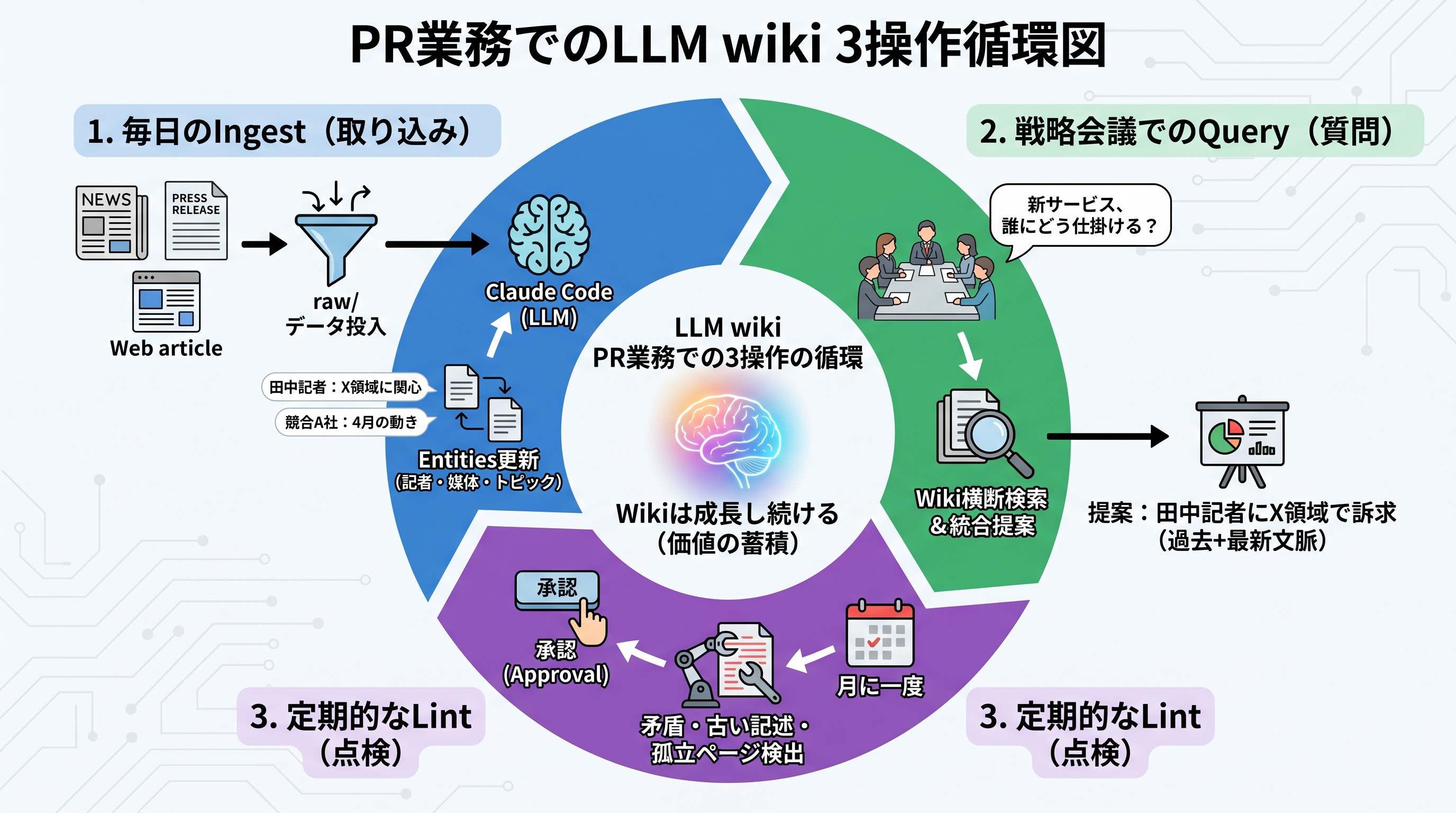
3つの操作が回り始めると、PR業務でこんな循環が生まれます。
毎日のIngest:業界ニュース、競合のプレスリリース、自社が掲載された記事、自社が受けたメディア問い合わせの記録。これらを raw/ に投げ込み、Claude Code に「Ingestして」と頼みます。LLMがそれぞれを読み、関連する記者・媒体・トピックのエンティティを更新します。「田中記者は最近X領域に興味を持ち始めた」「競合A社は4月にこのメッセージで動いている」といった文脈が、各エンティティページに自動で書き加わります。
戦略会議でのQuery:「来月リリースする新サービス、どの記者にどう仕掛けるべきか」とClaude Codeに聞きます。LLMはwikiの記者ページ・媒体ページ・過去キャンペーンログを横断して読み、直近のIngestで更新された情報まで含めて統合提案を返します。「田中記者は今月X領域の記事を書き始めたから、新サービスのこの側面で訴求するのが効く」のような、過去と最新の文脈を両方踏まえた提案になります。
定期的なLint:月に一度程度、「wiki点検して」と頼みます。LLMが矛盾(同じ記者の所属が複数ページで食い違っているなど)、古い記述(半年以上更新されていない記者の興味領域)、孤立ページ(どこからもリンクされていない素材)を洗い出し、修正提案を返します。承認したものだけwikiに反映されます。
この 取り込み → 質問 → 点検 のループを回し続けると、wikiは新しい情報で更新されながら、古い情報が腐らないまま育ち続けます。記者プロフィールも、競合動向も、業界トレンドも、一度作って終わりではなく、回し続けることで初めて価値が出ます。
業務利用なら追加したい『厳格モード』設定
カーパシーのGistでは、LLMの自動性と柔軟性が強調されています。基本方式はそれで十分です。一方で、業務、特に広報・PR業務に使うなら、追加で「厳格モード」を入れるのがおすすめです。
理由はシンプルです。LLMの推測が混ざった瞬間、後から「これは自分が言ったこと?LLMの補足?」が区別できなくなり、wiki全体の信頼性が崩れます。クライアント情報や記者プロフィールの誤情報は、PR業界では信用問題に直結します。
これを防ぐため、当社ではschema層(CLAUDE.md)に以下の6ルールを明記しています。ご自身でwikiを運用する際も、コピペで使えます。
| ルール | 中身 |
|---|---|
| 1 | 原典に書かれていることだけを保存する |
| 2 | 曖昧な箇所は必ず聞き返す(勝手に解釈しない) |
| 3 | wiki内検索による補強はOK、ただし出典明示が必須 |
| 4 | 要点抽出は原典の言い換えに留める(創作・補完はNG) |
| 5 | 不確かな分類は確認する |
| 6 | 「LLMの補足」を書きたくなったら我慢する |
このschemaファイルをそのままClaude Codeに渡せば、AIがこのルールに従って動きます。「業務で使えるwiki」と「ただのメモ置き場」の差は、この厳格モードの有無で決まります。
実装の定番:Obsidian × Claude Codeの組み合わせ
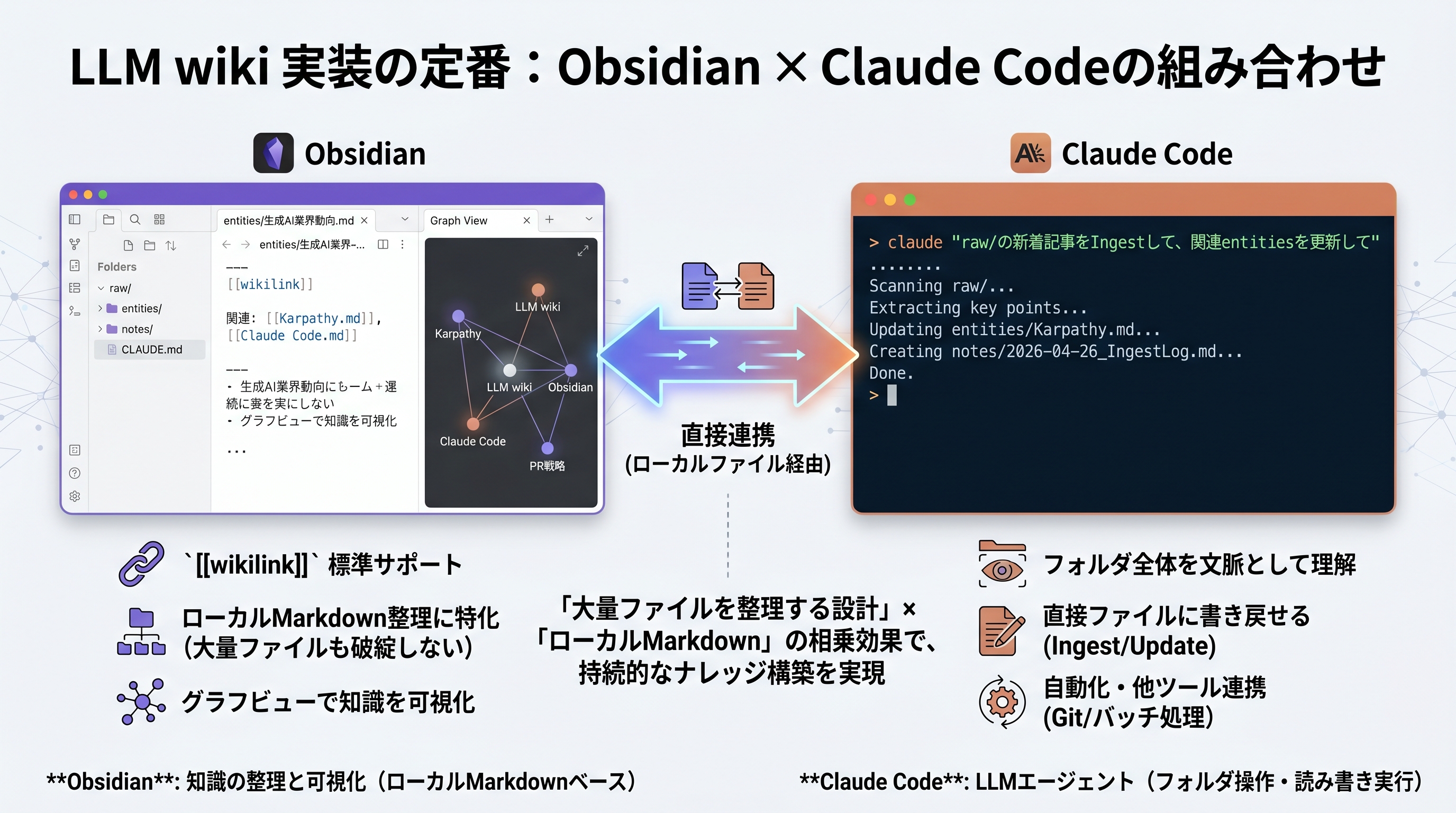
LLM wikiの実装ツールには色々ありますが、実践者の多くが選んでいる定番がObsidian × Claude Codeの組み合わせです。カーパシー本人もGistで「LLMエージェントを片側で開き、Obsidianをもう片側で開いている」「Obsidianのグラフビューがwikiの形を見るのに最適」と推奨しています。
Obsidianの強み3つ
Obsidianは、Markdownファイル形式で動くナレッジベース構築アプリです。無料で使えます。LLM wikiとの相性が際立って良い理由は3つあります。
| Obsidianの強み | LLM wikiとの相性 |
|---|---|
[[wikilink]] 記法を標準サポート | カーパシー方式の相互リンク構造をそのまま書ける |
| ローカルのMarkdownファイル群を整理することに特化した設計 | Vaultが数百〜数千のエンティティに育っても、検索・横断・タグ管理が破綻しない |
| グラフビューで知識ネットワークを可視化 | エンティティ同士の繋がりが一目で分かる、wikiの育ち具合が視覚化される |
特に重要なのは2つ目です。Obsidianは「Markdownファイルを大量に整理する」ための設計に徹底特化しています。フォルダ構造、タグ、検索、バックリンク、ペイン分割、すべてが「Vault全体を見渡しながら作業する」用途に最適化されています。NotionやEvernoteのようなDB型ツールでは、この体験は出せません。
加えて、ファイル本体はローカルのプレーンなMarkdownです。Claude Codeのような別ツールから、同じVaultを直接読み書きできます。「大量ファイルを整理する設計」と「ローカルMarkdown」の組み合わせが、LLM wikiの実装で選ばれる本当の理由です。
Claude Codeを選ぶ理由:Obsidianと同じファイルを直接読み書きできる
Claude Codeを選ぶ理由はシンプルです。Obsidian Vault のMarkdownファイル群を、Claude Codeが直接読み書きできること、これに尽きます。
「記者Aさんへのピッチ案を考えて」と頼むと、Claude Codeは entities/Aさん.md を起点に、ファイル中の [[日経新聞]] [[生成AI業界動向]] などのwikilinkをたどりながら関連ファイルを順次読み込み、最後にその回答を新しいノートとして notes/ に書き戻します。一連の動作が、一つのコマンド画面で完結します。
ファイルもwikilinkもフォルダ構造も、Obsidianで人間が管理しているものとまったく同じものを共有しています。**Obsidianを「人間用のビューア」、Claude Codeを「LLM用の作業エージェント」**として、同じVaultを別の入口から使い分けられる。これがこの組み合わせを選ぶ最大の理由です。
なぜ広報PR業務にLLM wikiは最適なのか
LLM wikiの考え方はPR業務に驚くほどフィットします。理由は5つあります。
理由1:蓄積データが多い
PR業界には記者プロフィール、メディアリスト、過去のキャンペーン記録、業界トレンド、競合動向、自社のメッセージング履歴が大量にあります。どれもエンティティ単位で整理できます。
理由2:関係性が複雑
「記者Aは媒体Bに所属、過去に競合C社の記事を書いた、今はトピックDに興味がある」のような複雑な関係が日常です。RAGのチャンクではこの関係性が分断されます。wikiのリンク構造ならそのまま表現できます。
理由3:文脈が成果を左右する
PRの世界では「誰に、いつ、どう伝えるか」の文脈設計が成否を分けます。文脈とは関連エンティティのネットワークそのものです。wiki構造はこの仕事と発想が一致します。
理由4:人間の判断が必須
戦略立案、メッセージング、危機対応は必ず人間が関与します。だからLLMだけが使う形式ではなく、人間も読めるwiki形式の方が実務に馴染みます。
理由5:継続的な関係構築が前提
PRは一発の取材で終わりません。同じ記者と数年単位で関係を育てます。だから過去の文脈を失わず蓄積する仕組みが必要です。wikiはこのために設計された形式です。
LLM wikiにも弱点が!?
ここまで LLM wiki の良さを語ってきましたが、カーパシー自身も書いている通り、これは万能薬ではありません。
規模の天井がある
カーパシー本人がGistで認めている通り、wikiが**中規模(〜数百ページ)**を超えると、index.md だけでは検索が追いつかなくなります。その場合は qmd(カーパシーも推奨するローカルmarkdown検索エンジン)のような道具を別途導入する必要があります。
Gistコメント欄に並ぶ批判
カーパシーのGistのコメント欄では、こんな指摘が並んでいます。
- 「結局これは構造化された永続コンテキストを再強調しているだけでは?AGENTS.md hierarchy + Skills でも同じことができる」(@skpalan)
- 「定期的なクリーニング・剪定のルールがないと、artifactsが手に負えなくなる」(@MironV)
- 「どこまでスケールするのか?」(@druce)
- 「チームでの共有はどう設計する?現状RAG + MCPサーバーでやっているが、LLM wikiでも同じ形でいけるのか?」(@geetansharora)
LLM wikiは「個人またはごく小さなチーム」のスケールで真価を発揮する仕組みで、大規模組織での共有運用や、巨大データの取り扱いには、まだ設計上の課題が残るようです。
しかしLLM wikiは生成AIを業務に活用していく上で、業務の効率化には不可欠な考え方になるのではないでしょうか。
カーパシーは本記事のLLM wikiだけでなく、自然言語でアプリを作る「Vibe Coding」、複数LLMで議論して結論を出す「LLM Council」、LLMと一緒に本を読む「Reader3」など、AIをうまく活用する方法を次々と生み出してくれる超天才。これからも活動に注目です。
「自社でwikiを育てたいが、最初の設計や運用ノウハウがほしい」という方は、お気軽にご相談ください。