この記事の要点
- 海外で「書き方を整えろ」派と「メディアに載れ」派の論争が過熱。答えは「両方」だが、最後に差がつくのは第三者メディアに取り上げられた実績
- 5社のAI(GPT-5、Gemini、Claude、Grok、Perplexity)に「信頼できる日本のメディア」を聞いたら、総務省が1位、NHKが2位で全社一致。SEOで重視されるドメインレーティングとはまったく連動していなかった
- AIは「質問の種類」でメディアを使い分けている。PR TIMESは事実確認で引用率96%と圧倒的だが、「評判」や「比較検討」では引用ゼロ
ゲームのルールが変わり始めている
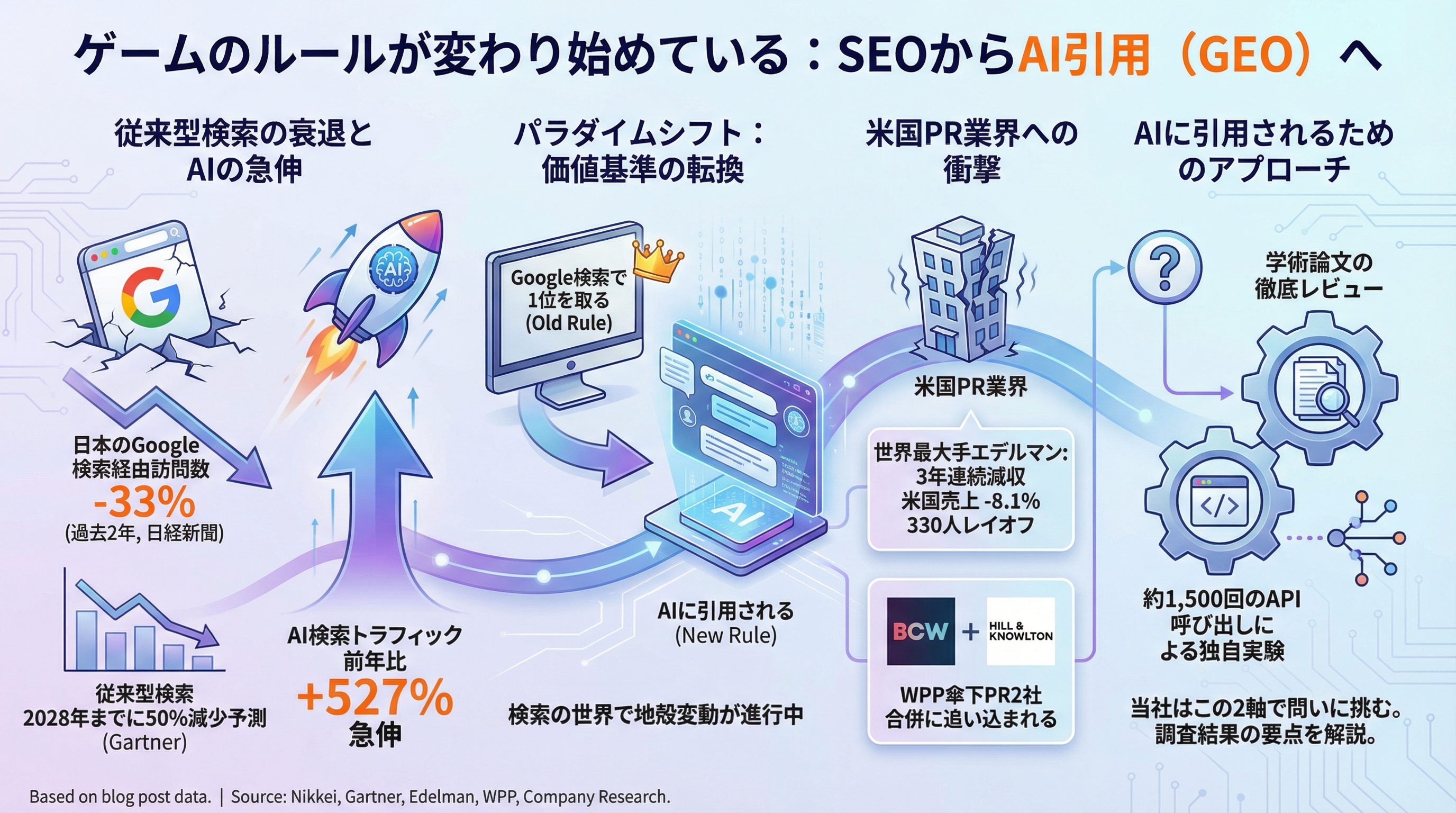
日本のGoogle検索経由の訪問数は、過去2年で33%減少(日経新聞)。一方、AI検索トラフィックは前年比+527%で急伸しています。Gartnerは2028年までに従来型検索が50%減少すると予測しました。
「Google検索で1位を取る」から「AIに引用される」へ。検索の世界で地殻変動が起きています。
米国ではこの変化がPR業界の根幹まで揺さぶっており、世界最大手のPR会社エデルマンは3年連続減収で米国売上は前年比-8.1%。330人をレイオフしています。WPP傘下のPR2社(BCW、Hill & Knowlton)も合併に追い込まれました。
では、AIに引用されるために何をすればいいのか。当社では学術論文の徹底レビューと約1,500回のAPI呼び出しによる独自実験の2軸でこの問いに挑みました。この記事では、両方の調査結果を要点だけまとめて紹介します。
学術論文が示す答え。「テクニック × 知名度」の掛け算
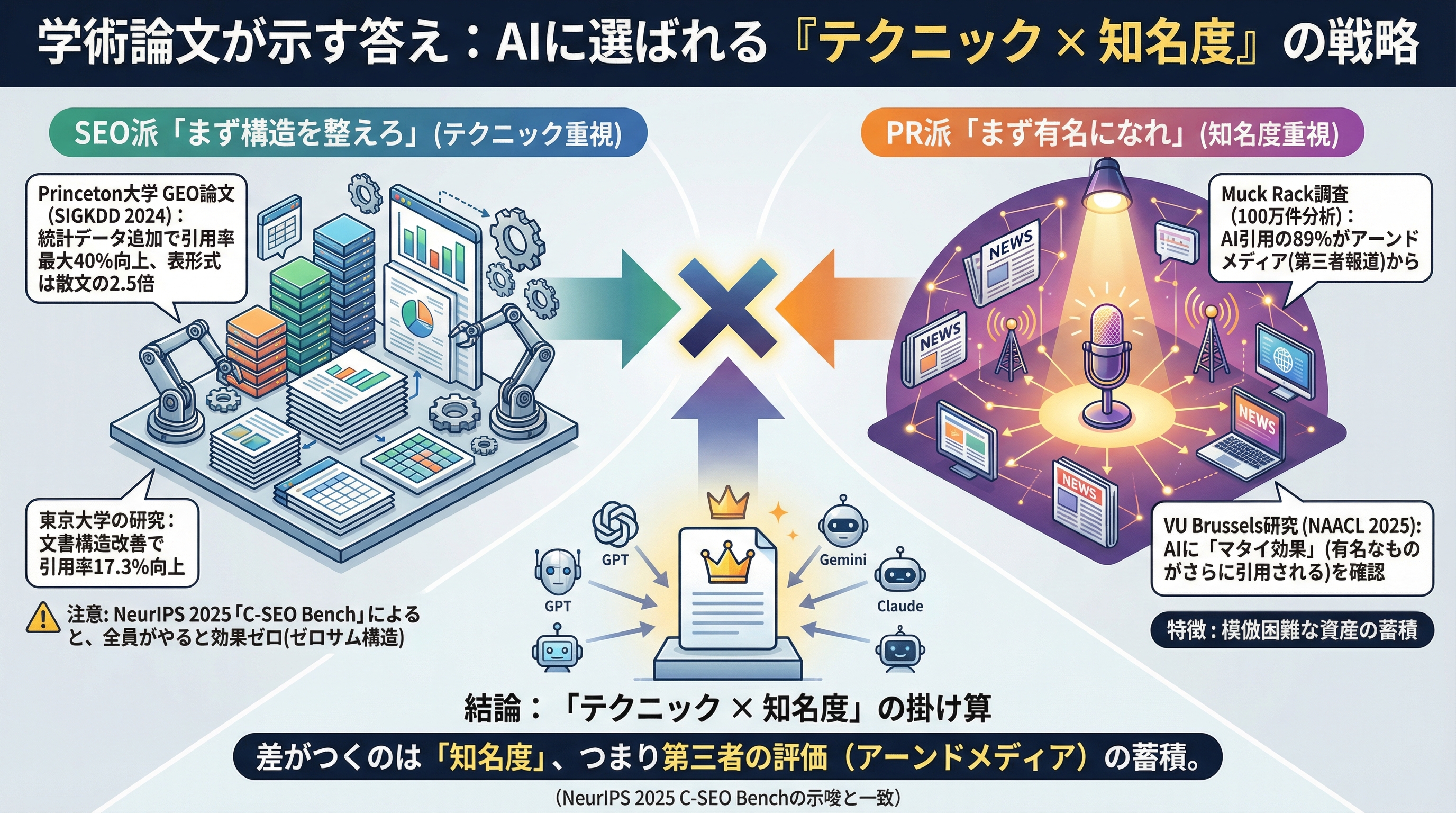
海外では2つの陣営がまったく異なる答えを出しています。
SEO派「まず構造を整えろ」
Princeton大学のGEO論文(SIGKDD 2024、査読済み)は、統計データを追加するだけで引用率が最大40%向上、表形式のコンテンツは散文の2.5倍引用されやすいと報告しています。東京大学の研究でも、文書構造を変えるだけで引用率が17.3%向上することが確認されました。
PR派「まず有名になれ」
一方、Muck Rackが100万件超のAI引用リンクを分析した結果、AI引用の89%がアーンドメディア(第三者が自主的に報じた記事)から来ていました。VU Brusselsの研究(NAACL 2025)は、AIに「マタイ効果」(有名なものがさらに引用される構造)が組み込まれていることを明らかにしています。
3つの論文を並べると、答えは1つに収束する
NeurIPS 2025採択の「C-SEO Bench」論文は、会話型SEO手法の大半は全員がやると効果ゼロになる(ゼロサム構造)ことを示しました。
つまり:
テクニック(構造化)は効く。しかし全員がやれば差がなくなる。差がつくのは「知名度」、つまり模倣困難なアーンドメディアの蓄積です。
これはPRの世界で昔から言われてきた「自分で操作できないもの(=第三者の評価)にこそ価値がある」という原則と一致します。
5社のAIに聞いてみた。総務省1位、NHK2位の完全一致

では日本のメディアをAIはどう評価しているのか。5社のAI × 主要23メディア × 3つの質問パターンで検証しました。
AIが選んだ信頼できるメディアTOP3
| 順位 | メディア |
|---|---|
| 1 | 総務省(全5モデル一致) |
| 2 | NHK(全5モデル一致) |
| 3 | 共同通信 |
Yahoo!ニュースは16〜18位、noteは22位、YouTubeは23位(最下位)でした。AhrefsのドメインレーティングでYouTubeは99(ほぼ満点)ですが、AIの信頼評価では最下位圏。SEO的な「権威」とAIの「信頼」はまったく別物だと分かります。
PR TIMESの約9万回引用の正体
AhrefsのBrand Radarによると、PR TIMESはAIに約9万回引用されており全ドメイン中2位。この数字の中身を分析すると、質問の種類でAIがメディアを使い分けている構造が見えてきました。
| 質問の種類 | PR TIMESの引用 | 代わりに引用されるメディア |
|---|---|---|
| 事実確認「トヨタの決算は?」 | 1位(96%) | — |
| 評判「トヨタの評判は?」 | ゼロ | 日経190回、NHK54回、朝日48回 |
| 比較検討「会計ソフト比較」 | ゼロ | 日経146回、ITmedia97回 |
PR TIMESは「公式発表の原典」としては圧倒的に強い一方、「評判」や「比較検討」の土俵では別のメディアが選ばれています。AIはプレスリリースと第三者報道の役割を正確に理解した上で使い分けているのです。
明日から動ける3ステップ
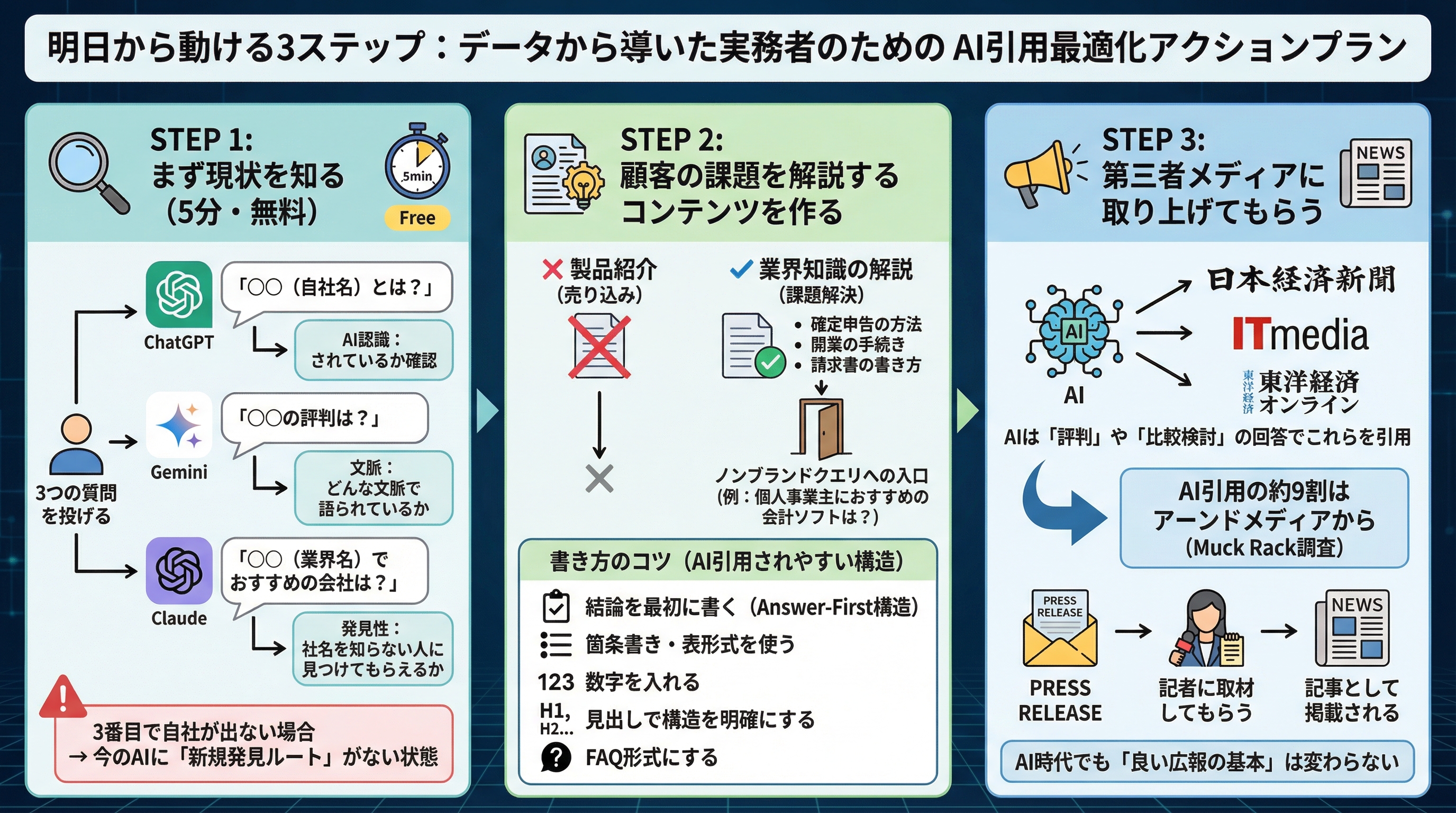
データから導いた、実務者が今日から取り組めるアクションです。
ステップ1: まず現状を知る(5分・無料)
ChatGPT、Gemini、Claudeに3つの質問を投げてみてください。
- 「○○(自社名)とは?」 → AIに認識されているか
- 「○○の評判は?」 → どんな文脈で語られているか
- 「○○(業界名)でおすすめの会社は?」 → 社名を知らない人にも見つけてもらえるか
3番目で自社が出てこないなら、今のAIに「新規発見ルート」がない状態です。
ステップ2: 顧客の課題を解説するコンテンツを作る
AI引用で上位に立っている自社ドメインの共通点は、製品紹介ではなく業界知識の解説記事で引用を獲得していたことです。「確定申告の方法」「開業の手続き」「請求書の書き方」など、自社の製品を売り込まない記事が、「個人事業主におすすめの会計ソフトは?」というノンブランドクエリへの入口になっていました。
書き方のコツ:
- 結論を最初に書く(Answer-First構造)
- 箇条書き・表形式を使う
- 数字を入れる
- 見出しで構造を明確にする
- FAQ形式にする
ステップ3: 第三者メディアに取り上げてもらう
AIが「評判」や「比較検討」の回答で引用するのは日経、ITmedia、東洋経済などの第三者メディアです。Muck Rackの100万件調査でも、AI引用の約9割はアーンドメディアから来ています。
プレスリリースを出して終わりではなく、記者に取材してもらい、記事として掲載されること。AI時代でも「良い広報の基本」は変わりません。
コラム: この調査の裏側。AIに調査させる「AutoResearch」という手法
今回の調査では、noteでは簡単にしか触れられなかったAutoResearchという手法を使っています。この面白い仕組みを詳しく解説します。
着想の元はカーパシー氏の「AutoResearch」
OpenAI共同創業者のAndrej Karpathy氏が2026年3月に公開したAutoResearchという実験が着想の元です。一言で言えば、「AIに研究者の役割をさせる」 やり方。
カーパシー氏のオリジナル版は、機械学習モデルの性能改善に特化しています。AIエージェントがコードを書き換え→5分間学習→指標(val_bpb)をチェック→良ければ残す→というループを延々と回します。2日間放置して700回の実験を自動実行し、11%の性能向上を達成しました。
ここで注目すべきは「判定が数値メトリックで完結する」という設計です。val_bpbは数学的に計算できるので、別のAIに「改善したか」を判定させる必要がありません。
今回の調査での応用と工夫
今回は同じ考え方をメディア研究に応用しました。ただしメディア信頼性のような主観判定が必要なテーマでは、カーパシー版のように「数値メトリックで自動判定」ができません。そこで、仮説を立てるAIと結果を判定するAIをループに組み込みました。
通常の研究フローはこうです。
人間が論文を読む → 疑問を持つ → 実験 → 結果を分析 → 論文を書く
これをAIに任せます。
AIが発見を読む → 仮説を立てる → LLMに聞いて検証 → 結果を分析 → 次の仮説を立てる
このループを自動で回し続けることで、人間が思いつかない角度の発見が湧いて出てきます。
通常のLLM利用と何が違うのか
ポイントは、プロンプト(質問文)自体もAIが自分で考えてくれることです。
通常のLLM利用では、人間が質問を考えてAIが答えます。
【通常のLLM利用】
人間が入力(質問) → LLM → 出力(答え)
AutoResearchでは、AIが「何を質問すればいいか」から考えます。
【AutoResearch】
LLM → 入力(質問を生成) → LLM → 出力(答え) → LLM(評価・次の質問へ)
人間は「調べてほしいテーマ」を渡すだけ。あとはAIが勝手に「この角度から聞いてみたら面白そう」と質問を組み立て、別のAIに聞き、結果を評価し、次の質問を作る、というループを回してくれます。
プログラムで書くとたった10行
AutoResearchの本質は、意外とシンプルです。擬似コードで書くとこんな感じになります。
# 「これまでの発見」リストに、初期の知見を入れておく findings = ["初期の発見1", "初期の発見2", ...] # このループを8回繰り返す for round in range(8): # 【研究者AI】今までの発見から、次の仮説を3つ考えてもらう hypotheses = ask_ai("この発見から仮説を3つ立てて", findings) # 立てられた仮説を1つずつ検証 for hypothesis in hypotheses: # 【実験装置】5社のAIに仮説のプロンプトを投げる results = ask_5_llms(hypothesis.prompt) # 【分析官AI】結果を見て、仮説が正しかったか判定 finding = ask_ai("仮説は支持された?", results) # 新しい発見をリストに追加(次のラウンドで使う) findings.append(finding)
たったこれだけです。ポイントは:
findingsという「発見のリスト」が少しずつ育っていく- 次のラウンドの仮説は、前のラウンドの発見を踏まえて生成される
- 人間が書いたプロンプトは
ask_ai("この発見から仮説を3つ立てて", ...)の1行だけ
従来の「人間が全ての質問を考えてAIに聞く」やり方と比べて、人間が書く質問文が激減します。人間は「AIに仮説を立てさせて検証させる」という枠組みだけ作ればよく、中身の質問はすべてAIが自動で埋めてくれるのです。
今回の調査での役割分担
今回の調査では、この仕組みをメディア研究に応用しました。内部では3つのAIが役割分担しています。
| 役割 | 仕事 |
|---|---|
| 研究者AI | 既存の発見を読み、「まだ検証されていない仮説」を3つ立てる |
| 実験装置 | 仮説に沿ったプロンプトを5社のAI(GPT-5、Gemini、Claude、Grok、Perplexity)に投げる |
| 分析官AI | 5社の回答を読んで、仮説が支持されたか棄却されたか判定する |
この3つがループで回り、発見が発見を呼ぶ構造になっています。
実際の結果
8ラウンド×3仮説 = 計24の仮説を自動検証しました。面白いのは完全に支持された仮説は1個だけで、残りの23個は「予想とは違う結果」だったこと。研究の価値は「思った通りの確認」ではなく「予想外の発見」にあることを、データが示しています。
人間では思いつかなかった「産経新聞が特定の質問パターンで評価対象から消える」「経済統計では日経ビジネスや東洋経済が全国紙を逆転する」「Geminiが中立性ランキングへの回答を拒否する」など、多様な発見が得られました。
コストと再現性
- 実行環境: Claude Code(Anthropic純正のAIコーディング環境)上で実装・実行
- 実行時間: 約3〜4時間(非同期処理で並列化)
- 保存形式: 全プロンプト・全回答・全分析をJSONで保存
人間の研究者なら数週間かかる仮説検証を、一晩で回せる。この手軽さが最大の魅力です。
改善の余地もあります
今回のPoCでは、研究者AIと分析官AIに同じモデル(Claude Sonnet 4.6)を使いました。実験装置の部分だけが5社のAIを総動員する設計です。同じモデルが仮説を立てて同じモデルが採点するため、理論的には「自分に甘い判定」のバイアスが入る可能性があります。
本番運用するなら、研究者AIと分析官AIを別のモデル(例: 仮説生成=Claude、判定=GPT-5)にする、あるいは複数モデルのアンサンブルで多数決にする、といった改善が必要です。今回はまず「AIに仮説検証を任せる」という方法論自体がメディア研究に通用するかを確かめるための実験と位置づけています。
マーケティング業界への応用可能性——AIに聞いてみた
AutoResearchは機械学習の世界で生まれた手法ですが、「データから新しい法則を発見する」というアプローチは、マーケティング業務にそのまま応用できます。
ここで一つ面白い実験をしました。「AutoResearchはマーケティングのどんな業務に使えるか?」という問いを、AutoResearch自体に考えさせてみたのです。
手順はこうです。
- 研究者AI(Claude Sonnet 4.5) に20個のユースケース案を生成させる
- 評価AI 3社(GPT-5 / Gemini 2.5 Pro / Claude Sonnet 4.5) が並列で採点
- 採点軸は「AutoResearch純度 / 実用性 / 実装容易性」の3つ
- 集約AI が合計点を計算してTop5を選出
実行時間約4分、コスト$0.3弱で、AIから次のような答えが返ってきました。
AIが提唱したTop5
| 順位 | ユースケース | AIが答える問い |
|---|---|---|
| 1位 | B2Bリードの『今すぐ客』変化点を自動検出するAI | リードが商談化する直前に見せる行動パターンの法則は何か |
| 2位 | 初回購入時の行動から3年後のLTVを予測する因子発見AI | 顧客の初期行動のどの組み合わせが長期的な優良顧客化を決定づけるのか |
| 3位 | クロスセル成功の黄金方程式を発見するAI | どの商品をいつ、どの順番で提案すると購入確率が最大化するのか |
| 4位 | カート放棄の隠れた心理的要因を探索するAI | 価格や送料以外に、どんな要因がカート放棄を引き起こしているのか |
| 5位 | 優良顧客が3ヶ月目に離脱する真因を探索するAI | なぜ特定の優良顧客層が決まったタイミングで突然離脱するのか |
どれも共通しているのは、「何かを作る」のではなく「データから法則を発見する」というAutoResearch本来の使い方です。
1位「B2Bリードの『今すぐ客』変化点を自動検出するAI」の中身
例えば1位のユースケースはこう動きます。MAツール(マーケティングオートメーション)には大量の行動ログが蓄積されているものの、どの行動の組み合わせが商談化のサインなのか、人力では発見困難です。AIが過去の商談化リードの行動を分析し、隠れた法則を自動発見します。
- 研究者AIが、商談化したリードの行動履歴から時系列パターンの仮説を生成
- 非商談化リードとの比較で、仮説を統計的に検証
- 発見したパターンの前後関係から、新たな行動シーケンスの仮説を生成
- より精緻な商談化トリガーの条件を特定し、ループが進化
想定される発見の例:
「資料DL後7日目に価格ページを訪問し、その3日後に導入事例を3件以上閲覧したリードの商談化率は68%」
これまで「とりあえず資料DLした人に電話する」という荒い対応で取りこぼしていた見込み客を、具体的な行動シーケンスとして発見できます。営業が動くべきタイミングが、勘ではなくデータで決まるようになります。
AIから届いたメタ観察
集約AIは最後に、興味深いメタ観察も残してくれました。
AutoResearchが最も威力を発揮するのは、人間の直感では気づきにくい「行動パターンの組み合わせ」や「タイミングの法則」を発見する領域。特にB2BリードスコアリングやLTV予測など、長期的な顧客価値に関わる複雑な因果関係の解明で高い評価を得た。実装可能性が高く、かつビジネスインパクトが大きい領域での応用が期待される。
つまりAIは自分で「AutoResearchが最も向いているのは『行動パターンの組み合わせ』や『タイミングの法則』を解明する領域」という結論を導き出しました。人間が先入観で「キャッチコピー生成が一番有望」と思い込んでいたら、この結論には辿り着けなかったかもしれません。
まとめ
AIに選ばれるために必要なのは、「テクニック × 知名度」の掛け算です。コンテンツの書き方は必要条件、第三者メディア露出による知名度は差別化の源泉。どちらか片方では不十分です。この結論は、学術論文と1,500回の実験データが示しています。
当社では生成AIを活用した様々な運用サポートを行っています。「AIに自社が引用されているか知りたい」「どこから手をつけるべきか相談したい」「業務にAIエージェントを導入して効率化させたい」という方は、お気軽にお問い合わせください。
📖 調査の全詳細はnoteで公開中: